Implementing Clean Architecture, DDD-style, with .NET Core

Naam: Albert Starreveld
Huidige functie: Software Developer .NET
In 2017 Uncle Bob wrote a great book about clean architecture. It explains the principles of a good software architecture. The book contains lots of information about the SOLID principles, about boundaries in the application, about screaming architecture, and so forth. What’s great about the book, is that it isn’t dogmatic. It doesn’t have code samples explaining how to implement a use case or a controller. However, at some point you need to start coding. This leads to the question: What could a clean architecture look like? In this article I’ll explain my take on clean architecture.
The Clean Architecture
Robert C. Martin wrote a book and a webpage about clean architecture. The schematic representation of the clean architecture looks like this:
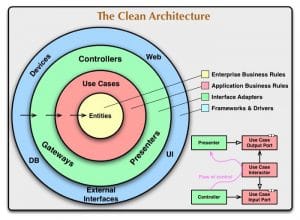
In this schematic representation, they architecture looks like an onion. It has layers. Each layer has a boundary. All dependencies point inwards. As a result, the closer you get to the core, the fewer dependencies the code has.
1.) Entities
In contrast to older architectures, the database is not the centre of the application any more. The business rules are.
It’s quite abstract. In the clean architecture, business-rules are implemented at the core of the application: in the use-cases, and in entities. But when is something an entity? And what is a use-case?
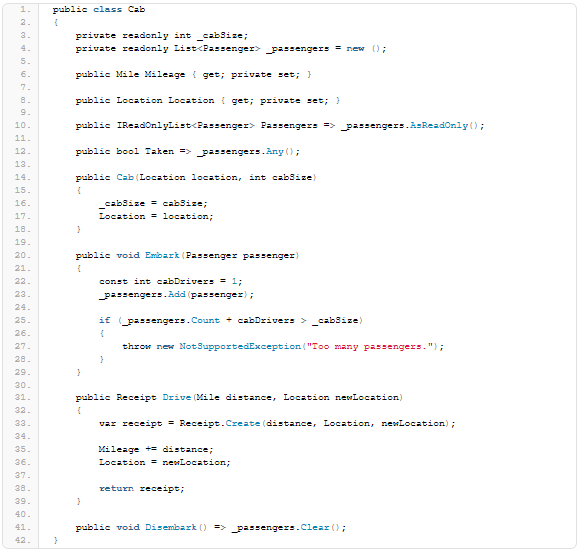
Assume we’re working on a cab dispatching application. Dispatching needs to dispatch a cab to a location. A location is defined as a longitude and a latitude. A valid longitude must be + or — 180 degrees. This is an example of a business rule. Implementing this as an entity at in the core of the application could result in this struct:


Crossing the boundaries
The rule of clean architecture is: all dependencies point inwards. The entities are at the core of the application, the are use-case layer depends on the entities, and the infrastructure layer depends on the use-cases.
As you can see in the sample-code, the use-case layer interacts with infrastructure too. Like the database, for example. That makes the use-case layer seem dependent on the infrastructure layer. But with Clean Architecture, it should be the other way around. So how does that work?
At the core of the application, you’ll find entities, use-cases, and interfaces. These interfaces define what the outside layers will look like and how the use-cases will interact with it. But the implementation is not at the “core” of the application. It’s implemented in another layer. That’s how the boundary is crossed.
There are two types of interaction with use-cases. The use-cases interact with the system, or a system interacts with the use-cases. In ports-and-adapters, these are called the primary- and the secondary ports.
A primary port is an interface to something the application will respond to. Like a keyboard, for example. When you hit enter, the application will do something.
A secondary port is an interface to a system the application interacts with. Like a database. The application is operating the database. It sends it instructions, and the database responds to it.
Screaming architecture
In most of the applications I’ve worked with, this is what the folder structure looks like:

We have a tendency to group things by type. But this makes it unclear what the application does with these types. Not to mention it’s failing capacity to scale. Try putting 300 entities in a folder. It will be a mess.
Instead, focus on the functionality of the application. We are building a cab dispatching application. So, group everything by functionality, and have the application screaming “CABS!!! CAB DRIVERS!! I’M A CAB DISPATCHING APPLICATION!!!”. It should be clear what the application does by it’s file- and folder structure only, without reading a single line of code. Put interfaces, entities, and use-cases in the same folder. By grouping by functionality, the application will grow organically and remain easy to navigate:

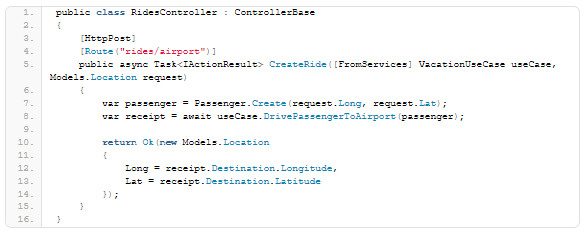
3.) Controllers
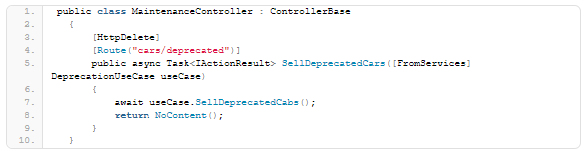
The use cases and the entities are the core of the application. By invoking one, or a sequence of use cases, an application can achieve a business goal. There are several “things” that can do this. In case of an event-driven application, a command handler will typically invoke the use-cases. In my case, I’m building a REST API, and the consumer of the API can invoke the use-cases directly. A simple controller will look like this:

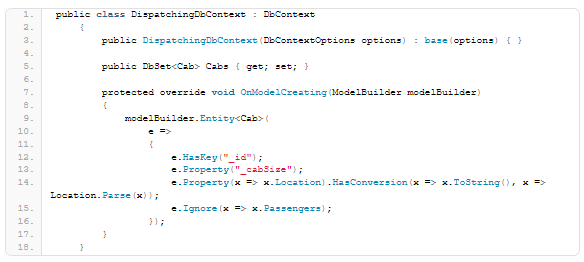
4.2) Other infrastructure
Clean architecture projects often have a “Infrastructure” folder. This folder contains the adapters to the bits of infrastructure the application uses to accomplish things:

This application uses:
- Google maps to calculate distance and to find the nearest airport
- The imaginary JunkyardAndCo webservice to sell cars
- SqlServer to store the state of the entities
- Western Union to handle financial transactions
Putting it all together
There are lots of concepts in the Clean Architecture. There are several ways of having that manifest in an actual application. I’ve built a simple .NET Core application with — what I think — is clean enough. Check it out: https://github.com/appie2go/clean-architecture let me know what you think!
Gerelateerde blog posts

Dit is het verschil tussen een software engineer en een computer scientist
Deze blog is voor jou wanneer jij werkzaam bent als IT’er in de softwarebranche, maar het nog steeds lastig vindt om het precieze verschil tussen een software engineer en een computer scientist te identificeren.
.jpg?width=390&name=7D5A5429%20(2).jpg)
5 manieren om jouw kennis als software developer te testen
Als software developer is het van cruciaal belang om voortdurend je kennis en vaardigheden op het gebied van programmeren te testen en te verbeteren. Lees snel de blog om erachter te komen hoe je jouw skills op de proef kunt stellen!

De 7 voordelen die jij meebrengt als een full stack developer
Als developer beschik je over een unieke kracht om de Nederlandse maatschappij vorm te geven en positieve veranderingen teweeg te brengen. Benieuwd hoe? Lees deze blog!
